基于数据库号段模式实现分布式ID
1.背景
唯一ID是业务系统操作数据的重要凭据。如果是单表,采用数据表的自增主键作为唯一ID即可。在分布式和高并发场景下,数据快速增长,单表可能被拆成多表,如果使用自增主键作为唯一ID,每个表都要设置不同的增长步长,不便于数据库扩展。在复杂的业务场景中,ID仅仅唯一是不够的,以订单号为例,至少要达到下面的要求:
- 全局唯一
- 规则简单,不能太长,便于内部人员沟通,外部人员无法猜测到订单量
- 趋势递增,有利于数据库查询
综合考虑以上三点要求,采用订单时间加上递增整数是较好的方案,如下图所示:
 订单号分区
订单号分区- 前区:14位数字的时间字符串,精确到秒
- 后区:6位递增整数,取值范围是000000到999999。
这种规则理论上1秒内包含不重复的订单号1000万个,满足业务需要。
订单号是按需生成的,比如第一次生成10个订单号,使用1到10,第二使用11到20,这种方案称之为号段。每次使用的号段必须稳妥可靠的记录下来,保证不重复使用。
2.详细设计
为了便于其他业务系统调用,需要提供一个独立的微服务,数据库采用MySQL,如下图所示:
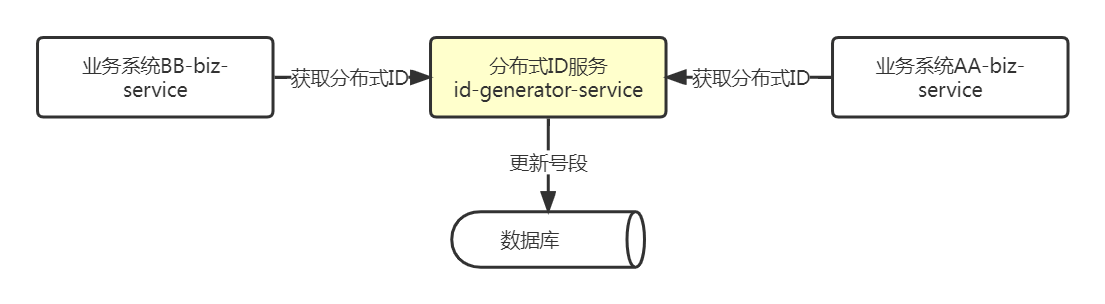 分布式ID服务
分布式ID服务每次生成订单号都把当前号段缓存起来,减少与数据库的交互。
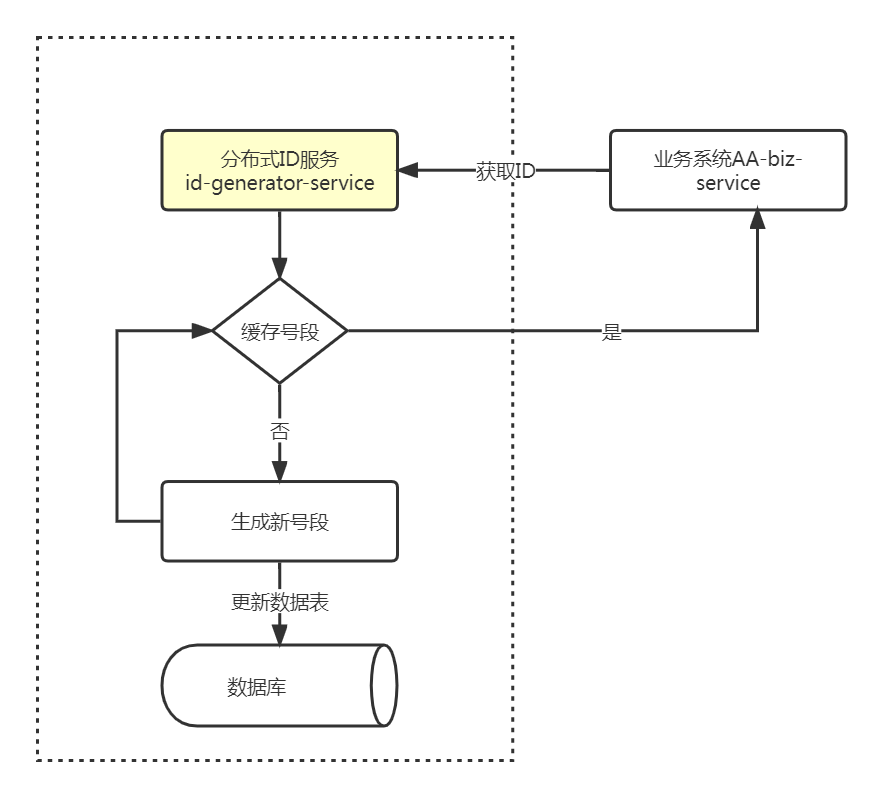 缓存号段
缓存号段号段数据表segment_id设计如下:
CREATE TABLE segment_id (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(20) NOT NULL COMMENT '号段的步长',
biz_type int(20) NOT NULL COMMENT '业务类型',
version int(20) NOT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
) - biz_type :代表业务类型,1表示订单号
- max_id :当前最大的可用id
- step :号段的长度
- version :乐观锁,每次都更新version,保证并发时数据的正确性
max_id字段是bigint,它的最大长度是 2^63-1,理论上可以生成9223372036854775807个整数。但是我们只截取它的后6位。
在集群环境中,使用乐观锁更新数据,伪代码如下。
update segment_id set max_id = #{max_id + step}, version = version + 1 where version = # {version} and biz_type = 1
号段生成器代码如下:
public class CacheIdGenerator implements IdGenerator {
private IdGeneratorLogic idGeneratorLogic;
private Integer bizType;
private long[] cacheIds;
private AtomicInteger currIndex = new AtomicInteger(0);
public CacheIdGenerator(Integer bizType, IdGeneratorLogic idGeneratorLogic) {
this.bizType = bizType;
this.idGeneratorLogic = idGeneratorLogic;
}
@Override
public synchronized Long nextId() {
if (cacheIds == null || currIndex.get() == cacheIds.length) {
cacheIds = idGeneratorLogic.getBatchId(bizType);
currIndex.set(0);
}
return cacheIds[currIndex.getAndIncrement()];
}
@Override
public List<Long> nextId(Integer batchSize) {
List<Long> ids = new ArrayList<>();
for (int i = 0; i < batchSize; i++) {
Long id = nextId();
ids.add(id);
}
return ids;
}
}生成订单号代码如下:
/**
* 为每个业务创建不同的生成器
*
* @param bizType
* @return
*/
private IdGenerator getIdGenerator(Integer bizType) {
if (generators.containsKey(bizType)) {
return generators.get(bizType);
}
synchronized (this) {
if (generators.containsKey(bizType)) {
return generators.get(bizType);
}
IdGenerator idGenerator = new CacheIdGenerator(bizType, idGeneratorLogic);
generators.put(bizType, idGenerator);
return idGenerator;
}
}
@Override
public String getIdByBizType(Integer bizType) {
IdGenerator idGenerator = getIdGenerator(bizType);
return LocalDateUtil.formatCurrentDate() +
StringUtils.leftPad(String.valueOf(idGenerator.nextId()), 6, "0");
}
完整代码地址:
https://gitee.com/cabbage/java-study-demo/tree/master/id-generator-demo
3.故障预测
- 数据库宕机
如果数据库宕机,max_id可能保存失败。恢复之后,即使max_id不正确,订单号前区的日期时间必定与宕机前不同,因此不会出现重复订单号。
对于MySQL数据库,建议设置参数innodb_flush_log_at_trx_commit为1,以保证数据不丢失。
- 服务宕机
服务宕机后丢失缓存在内存中的未使用的订单号,重启后生成新的,这个损失忽略不计。
4.Redis方案
利用Redis的incr命令也能实现号段方案,该命令可以对后区的整数原子性自增。
// 初始化自增ID为1
127.0.0.1:6379> set segment_id 1
OK
// 增加1,并返回递增后的数值
127.0.0.1:6379> incr segment_id
(integer) 2
相比传统关系型数据库,Redis并发能力极强。它提供的两种数据持久化方式RDB和AOF,在宕机后恢复数据会可能遇到如下情况:
- RDB方式:定时持久化数据快照。segment_id没及时持久化,重启后会出现重复。由于订单号前区是日期时间,避免最终的重复。
- AOF方式:保存所有写操作。即使宕机也不会出现重复。但incr命令会被多次执行,恢复的数据时间很长。
5.参考
https://blog.csdn.net/luoqinglong850102/article/details/105882694
https://segmentfault.com/a/1190000040289723?utm_source=tag-newest
https://blog.csdn.net/qq_35423154/article/details/115335736
https://segmentfault.com/a/1190000022717820
https://blog.csdn.net/a1036645146/article/details/109525522
https://www.freesion.com/article/2227459581/
本文链接:https://www.codingbrick.com/archives/532.html
特别声明:除特别标注,本站文章均为原创,转载请注明作者和出处倾城架构,请勿用于任何商业用途。
